Learnings from the APGCE Geohackathon 2024: Using AI to Identify Faults in 2D Seismic Images
Discover how AI tackled fault detection in 2D seismic data at the APGCE Geohackathon 2024. Learn about challenges with raster images, subjective fault picks, and how we used YOLOv11 and data augmentation to achieve 90% accuracy, creating a real-time fault prediction app, Fault Handler


This year marked my third time participating in the APGCE Geohackathon, an event I eagerly anticipate. What sets this hackathon apart is its unique focus—it's one of the few in-person machine learning competitions in the Asia-Pacific region dedicated to tackling challenges in the oil and gas sector. The event, backed by industry giant Petronas, consistently draws a mix of geoscientists, data scientists, and engineers eager to push the boundaries of innovation in energy exploration.
As a geologist, I’ve historically steered clear of seismic-related challenges. My prior experience with seismic data was limited to seismic interpretations, and the thought of handling SEG-Y traces—especially within the tight 48-hour timeframe—felt daunting. The complexities of loading, visualizing, and processing seismic data in open-source software have always been a roadblock for me. However, this year, I had no choice but to dive in. The two available challenges were both seismic-focused: predicting faults or horizons from seismic data using AI.
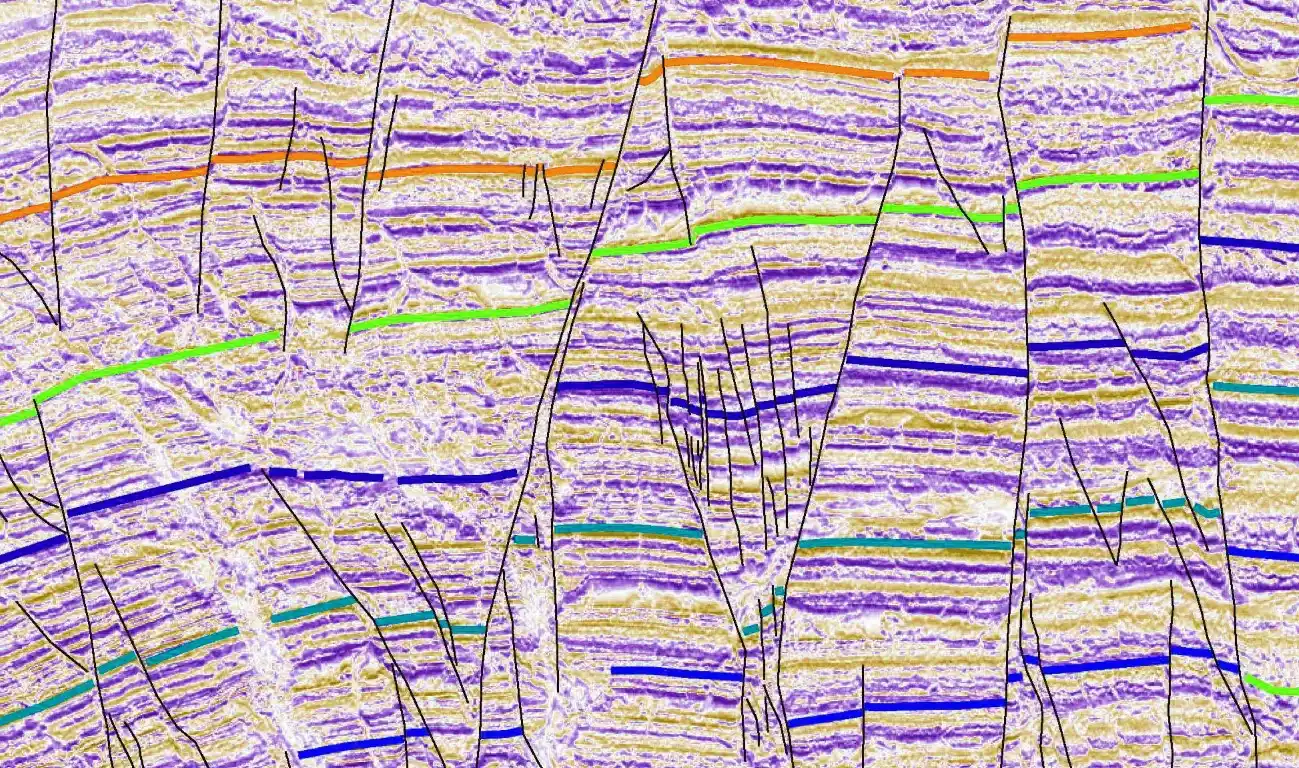
A Shift in Approach to Seismic Data
Recognizing past hurdles faced by participants, the organizers made a notable adjustment this year. Instead of raw seismic data, they provided rasterized 2D seismic images. This decision made the initial stages of the challenge more accessible by eliminating the need for SEG-Y data processing. Alongside these images, they supplied labeled features in the form of raster masks for faults and horizons—an essential tool for supervised learning models.
While the raster data format was a welcome relief, it presented a new set of challenges. On one hand, working with images instead of traces streamlined data preparation. On the other hand, raster images lack the depth of information present in raw seismic traces, which meant that AI models had to rely solely on visual patterns rather than amplitude or phase data. This tradeoff became a key factor in how we approached the problem and shaped my overall learnings from the hackathon.
Tackling the Challenge: Predicting Fault Picks in 2D Seismic Sections at the Geohackathon
Challenge Goal
The objective of the challenge was clear: leverage AI to develop a solution that could automatically predict fault picks on 2D seismic sections. A unique aspect of this problem was its focus on 2D seismic data, as most existing solutions available online cater to 3D seismic data. This made the challenge particularly exciting and underscored its relevance in advancing seismic interpretation workflows.
From a data science perspective, this was a classic computer vision task—a segmentation problem. The goal was to train a model capable of identifying and segmenting the pixels corresponding to fault planes. From a geological viewpoint, fault planes are regions where visible displacement occurs within the subsurface. While these are relatively easy to visualize in animated models, identifying faults on seismic sections, particularly for the untrained eye, can be challenging.
Dataset and Challenges
We were provided with 355 pairs of seismic images and their corresponding fault labels in the form of raster masks. While this format streamlined initial workflows, it introduced several limitations:
- Limitations of Raster Image Format
Seismic data is traditionally stored in SEG-Y files, where amplitude traces capture changes in subsurface density caused by variations in lithological layers. Converting this rich dataset into raster images strips away valuable amplitude information, replacing it with simple pixel data. This significantly reduces the available information and poses challenges in achieving high-accuracy predictions.
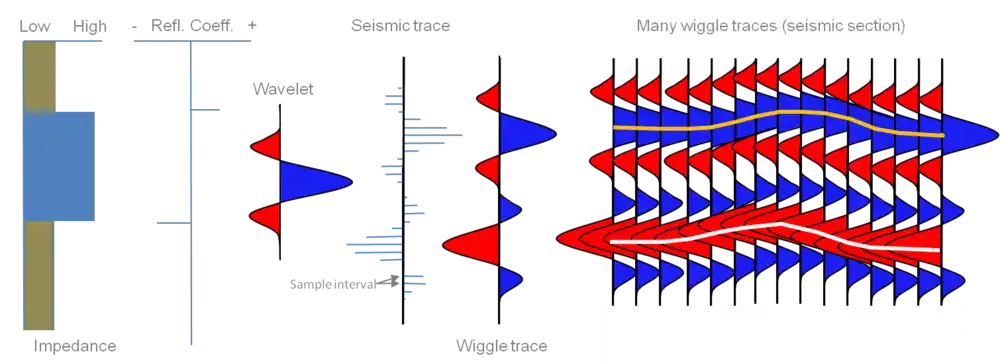
- Issues with Human-Labeled Fault Picks
Fault interpretation is inherently subjective, as geoscientists manually draw fault lines on seismic sections based on visual observation. When comparing fault picks from different geoscientists for the same section, significant variability is common. This variability stems from the interpretive nature of geology, a field that often thrives on qualitative assessments.However, machine learning demands precision. Inaccurate or inconsistent labeling can confuse the model, as it struggles to distinguish genuine fault planes from mislabeled regions. Unfortunately, the dataset provided for this challenge suffered from considerable label inconsistency, making model training and evaluation more difficult. - Uniformity of the Dataset
For a machine learning model to generalize effectively, it needs exposure to diverse datasets. The challenge dataset consisted of seismic sections from the same basin with regular offsets. While this uniformity was acceptable for the hackathon (where evaluation was conducted on holdout images from the same basin), it limited the model’s applicability to other basins and seismic datasets, reducing its real-world utility.
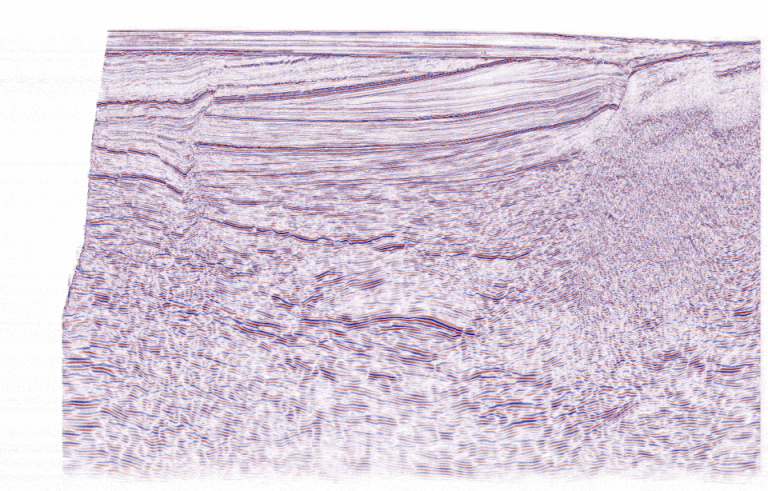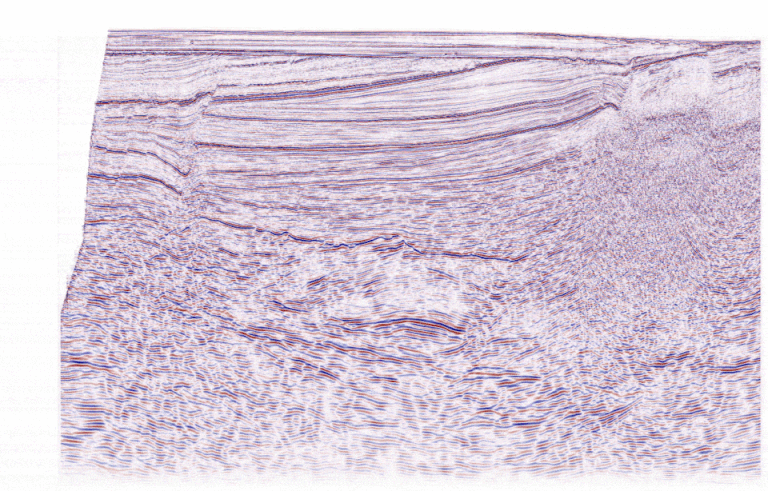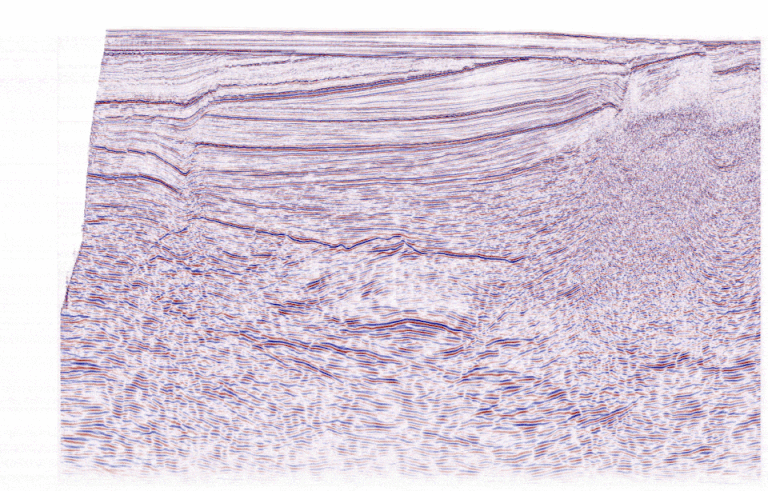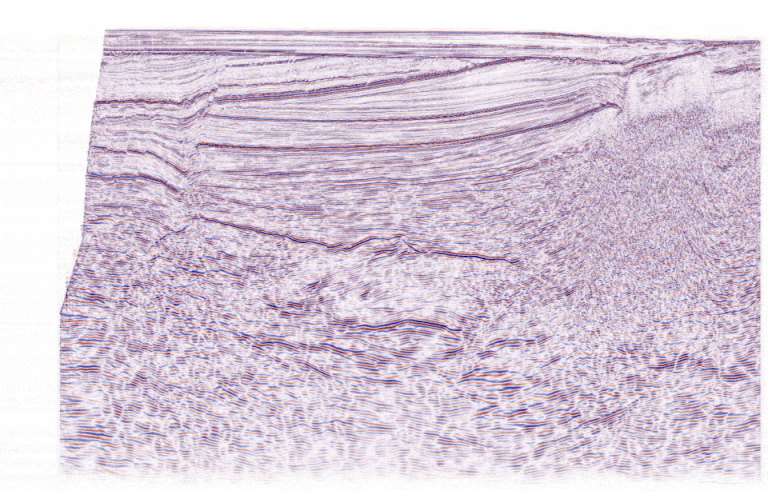
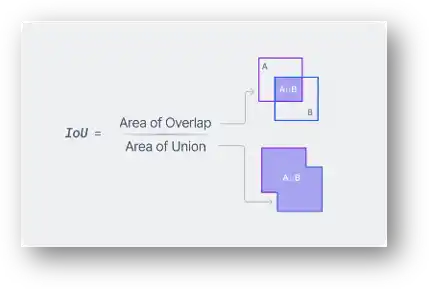
Recommende Judging Metric: Mean IOU
The metric for evaluating the models was Mean Intersection Over Union (Mean IOU). This metric measures the overlap between the predicted fault mask and the ground truth labels, essentially assessing how accurately the model identifies fault planes.
However, this approach hinges on the reliability of the ground truth labels, which, as discussed earlier, were human-generated and prone to subjectivity. Inconsistent labels undermine the accuracy of evaluation, raising questions about the fairness of the metric in a domain as interpretive as geology. Below is an example illustrating the variability of fault picks by three different geoscientists, emphasizing the inherent challenges of relying on human-labeled ground truth data.

Recommended Models and Technical Challenges
The hackathon committee recommended a range of models, primarily from the convolutional and recurrent neural network families, such as U-Net and CrackNet. They also provided teams with pre-written code and access to a Microsoft Azure VM equipped with a Tesla T4 GPU to streamline the process.
Despite these resources, several challenges emerged:
- Code Modifications
While the provided code worked for sample images, it required extensive customization to process the full dataset and achieve reasonable performance. Teams with data scientists familiar with PyTorch and deep learning techniques were better equipped to address these issues but still faced hurdles. - Hardware Limitations
The Azure VM’s 16GB GPU posed a bottleneck. Even with a batch size of 1, teams struggled to load and process images efficiently. Optimizing network layers and memory usage became critical to producing any meaningful results. - Suboptimal Accuracy
Despite overcoming these technical hurdles, many teams found that their models produced only suboptimal results. Fine-tuning the models within the limited timeframe was a significant challenge, and the inherent issues with the dataset compounded these difficulties.
A Change in Approach
By the end of the first day, our team realized that continuing with the recommended CNN and RNN approaches might not yield significant improvements in the remaining time. We decided to pivot our strategy, leveraging alternative techniques to improve fault prediction accuracy.
How We Addressed the Challenges and Delivered Results
The seismic fault-picking challenge came with several hurdles, but our approach tackled these effectively by rethinking metrics, preprocessing strategies, model selection, and deployment. Here’s how we solved the problem and accounted for the complexities:
Metric Selection: A Qualitative Approach
Recognizing the limitations of quantitative metrics like Mean IOU in a domain as interpretive as geosciences, we opted for visual inspection as our evaluation criterion. Instead of relying solely on numerical accuracy, we visually assessed the fault predictions to check:
- Whether the model missed any fault planes.
- Whether the model incorrectly plotted faults in the wrong locations.
The results were evaluated by multiple geoscientists to minimize individual biases, and the scores were averaged. This approach better aligned with the qualitative nature of geological fault interpretation.
Image Preprocessing: Geologically Meaningful Augmentation
Given the limited dataset size and the lack of variability in the seismic images, we implemented two custom image augmentation techniques that made geological sense:
- Image Compression and Shearing
By stretching, compressing, and shearing seismic images, we simulated the appearance of different geological conditions. This added variability to the dataset, enabling the model to generalize better during training. - Simulated Coherence
Coherence is a seismic attribute that enhances the visibility of edges, such as fault planes, in seismic data. We applied curve adjustments to create a similar visual effect, making the fault planes more pronounced.
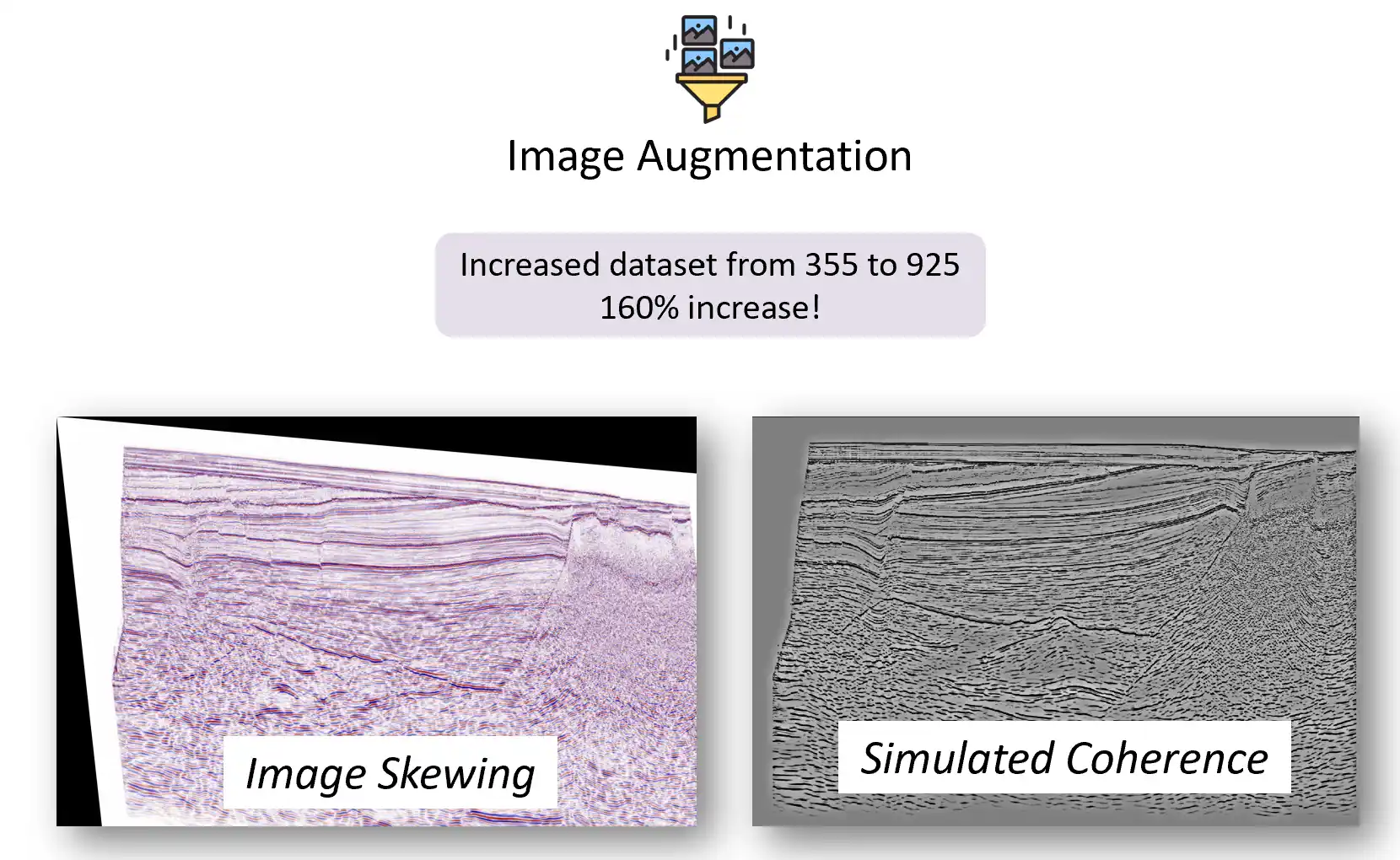
These augmentations expanded the dataset by 160%, significantly improving the model's ability to detect faults accurately.
Model Selection and Training
To address challenges with the suggested CNNs and RNNs, we shifted to the YOLO (You Only Look Once) family of models. This decision offered several advantages:
- Efficient Image Segmentation
YOLO models excel at image segmentation and detection, enabling faster and more precise identification of fault planes. - Reframing the Problem
YOLO allowed us to reframe the task as instance segmentation rather than conventional semantic segmentation. This approach provides the flexibility to classify faults by type (e.g., normal faults, reverse faults) in future iterations.
We trained a YOLOv11 instance segmentation model for 100 epochs, adhering to standard data science practices like learning rate optimization and validation checks. The model achieved over 90% accuracy, a satisfactory result for the hackathon’s objectives.

Deployment: Faults Handler App
In addition to model development, we focused on deployment. Our solution included a fully functional app named Faults Handler, featuring:
- Frontend: Built with React for a user-friendly interface.
- Backend: Powered by FastAPI for seamless data processing.
- Speed: The app could process seismic images and return annotated outputs at a rate of 10 images per second.

This end-to-end solution demonstrated the practical applicability of our approach and made our submission stand out.
Results: A Close Finish
Our solution secured the 1st Runner-Up position, missing the top prize by just 0.2 points. Despite this, the recognition validated our innovative approach and highlighted areas for further improvement.

How This Can Be Improved for Industrial Use
While the hackathon solution was promising, there are several ways it could be refined for real-world applications:
- Pre-Training on Synthetic Seismic Datasets
- By creating synthetic SEG-Y seismic sections with simulated fault planes, we can generate highly accurate labels directly on fault planes.
- This synthetic dataset would address issues of label variability and dataset generalization.
- Pre-training on this data would create a robust base model, which could then be fine-tuned with basin-specific human-labeled datasets.
- Combining Instance Segmentation with Large Language Models (LLMs)
- Once the model accurately predicts and classifies faults, it could process entire seismic projects.
- These results could be fed into a vision-enabled LLM to generate a first-pass structural interpretation of the area.
- This integration would streamline workflows, saving time and providing geoscientists with a solid starting point for detailed interpretations.
Conclusion
Participating in the APGCE Geohackathon 2024 provided an incredible learning experience, bridging the gap between AI and geoscience. By addressing key challenges through innovative solutions, we pushed the boundaries of seismic fault interpretation within a short timeframe.
While our solution performed well in the hackathon, its potential for industrial application is immense with further enhancements. From pre-training with synthetic datasets to integrating LLMs for advanced structural interpretations, the possibilities are exciting.
Stay tuned as we refine this approach and continue to explore the transformative potential of AI in geosciences!